
A Lightweight Thread based storage runtime
Background
Massive concurrency is the primary signature of Enterprise storage IO workloads. POSIX threads, a.k.a. pthreads, implemented in a Unix-like OS are too “heavy” to effectively support such concurrency.
The overhead incurred by pthreads can be grouped into two main areas:
1) memory cost of maintaining thread computational state, which includes duplicating all registers and data (stack, heap) plus memory associated with tracking the thread-state;
2) context switch cost, which includes cost of changing processors context (registers, counters etc) and changing computational context (interrupts, scheduling and processor and RAM cache).
These costs put a physical limit on how many pthreads a system can have and dictates how often a context switch may be profitably utilized.
User space lightweight threads (ULTs) are an alternative to traditional threads. ULTs allow a number of logical threads to share a thread context in a single physical pthread, thereby reducing memory consumption. A non-preemptive user space scheduler allows an application to switch between lightweight threads without involving the OS/kernel system scheduler. We can envision a runtime/library, which combines the features of a) sharing a single physical thread and b) user space scheduling. This runtime will have the advantage of being more efficient for managing large numbers of short-duration work items. We should mention that we expect these work items to have few external dependencies such as system calls.
Argobots Runtime for Storage (ABT-ST)
There are many lightweight thread implementations. Proprietary Microsft UMS scheduler, open source Argobots are a couple of examples. The Argobots Runtime for Storage builds upon Argobots framework and serves the need of storage workload. The main goal is to provide support for some typical storage workload characteristics:
-
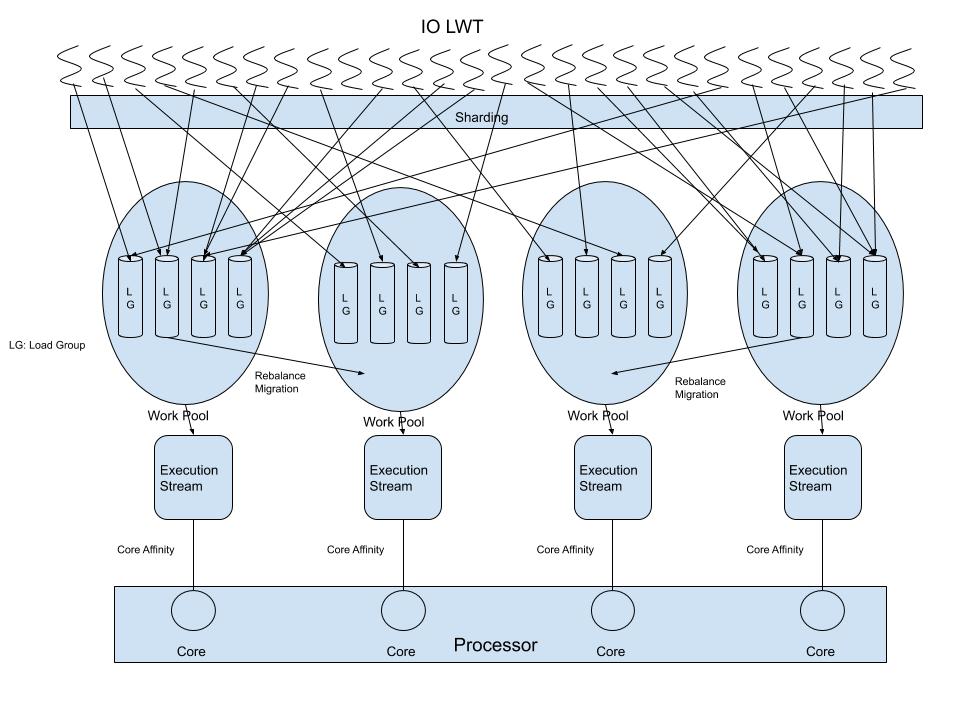
Mapping: A mechanism to evenly distribute I/O load across the available CPUS. When an I/O arrives, it is assigned to a lightweight thread (LWT), which is associated with a single load-group. A load-group has an OS thread that is bound to a single CPU core, and is shared by many lightweight threads (LWT). With the non-preemptive/cooperative user mode scheduler, instructions within the load-group are serialized and do not require a spinlock. This improves thread level parallelism, which is vital in today’s storage servers with large numbers of cores. It is especially important for ARM servers with hundreds of cores and multiple NUMA domains.
-
Workload rebalance: When the load among physical CPU cores becomes imbalanced, a rebalancer will redistribute LWTs to optimally utilize CPU resources. The algorithm for rebalancing will also take different NUMA topologies into consideration when deciding how to migrate load-groups to different CPUs. See diagram rebalance:
-
Stackable schedulers: Each load-group has its own scheduler, while a group of sequential instruction streams executed on a CPU core can have a main scheduler. This allows different types of load-groups to share a CPU core while keep their own scheduler. For example, front end write to cache IO load-group and backend write to disk IO load-group may share a CPU core, while keep their own low latency scheduler and high throughput scheduler.
The runtime source code is hosted at this github link. It is a work in progress as of today.